Corentin Salaun1, Xingchang Huang1, Iliyan Georgiev2, Niloy Mitra2,3, Gurprit Singh1
1Max Planck Institute for Informatics, Saarbrücken, Germany 2Adobe, United Kingdom 3UCL, United Kingdom
arXiv
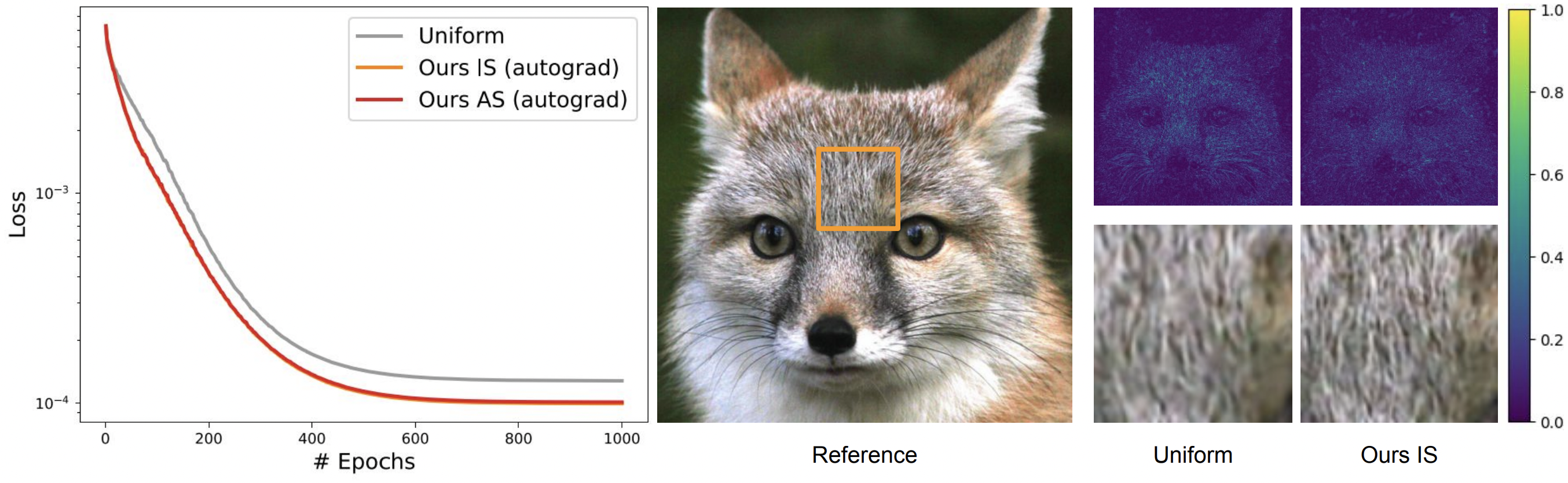
Image regression using a 5-layer SIREN network by Sitzmann et al. which is trained for
predicting RGB values from 2D pixel coordinates. Our importance and adaptive sampling strategies
based on autograd gradients show clear improvements compared to uniform sampling at equalepoch loss curves. We further show the error map and zoom-in results using uniform sampling and
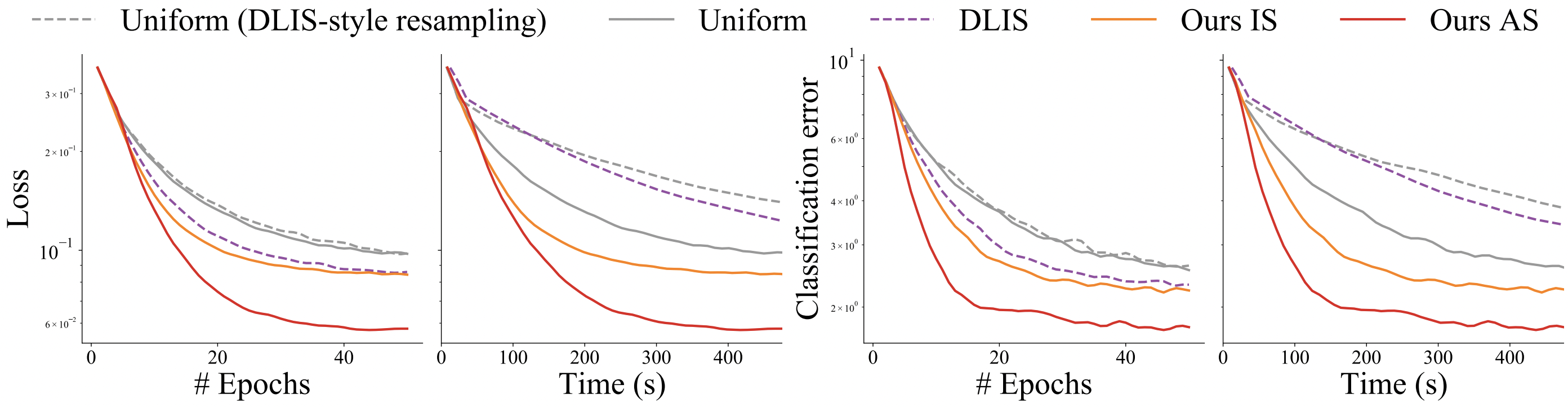
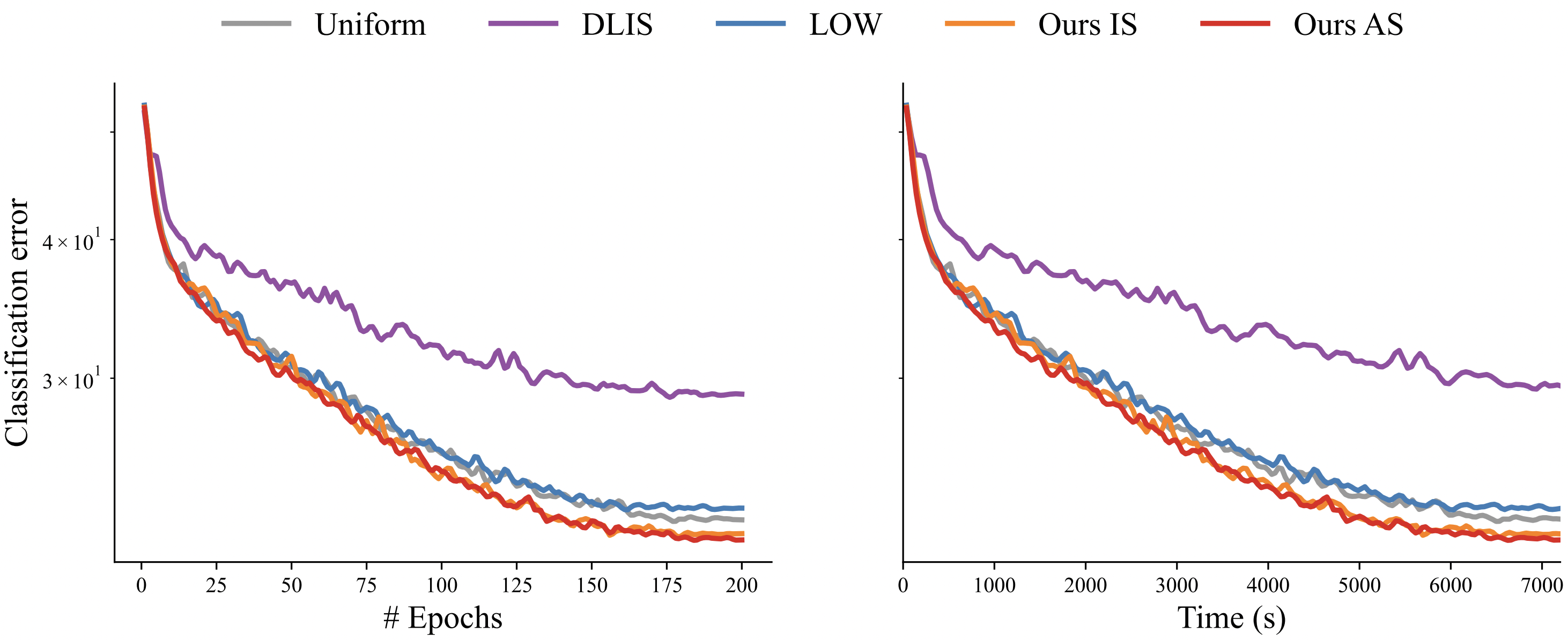
our importance sampling. Equal-time comparisons show similar improvements as shown in the main paper.
Abstract
Machine learning problems rely heavily on stochastic gradient descent (SGD) for
optimization. The effectiveness of SGD is contingent upon accurately estimating
gradients from a mini-batch of data samples. Instead of the commonly used uniform sampling, adaptive or importance sampling reduces noise in gradient estimation by forming mini-batches that prioritize crucial data points. Previous research
has suggested that data points should be selected with probabilities proportional to
their gradient norm. Nevertheless, existing algorithms have struggled to efficiently
integrate importance sampling into machine learning frameworks. In this work,
we make two contributions. First, we present an algorithm that can incorporate
existing importance functions into our framework. Second, we propose a simplified importance function that relies solely on the loss gradient of the output layer.
By leveraging our proposed gradient estimation techniques, we observe improved
convergence in classification and regression tasks with minimal computational
overhead. We validate the effectiveness of our adaptive and importance-sampling
approach on image and point-cloud datasets.