Best Student Paper Award (ICPRAM 2025)
Corentin Salaun1, Xingchang Huang1, Iliyan Georgiev2, Niloy Mitra2,3, Gurprit Singh1
1Max Planck Institute for Informatics, Saarbrücken, Germany 2Adobe, United Kingdom 3UCL, United Kingdom
ICPRAM 2025
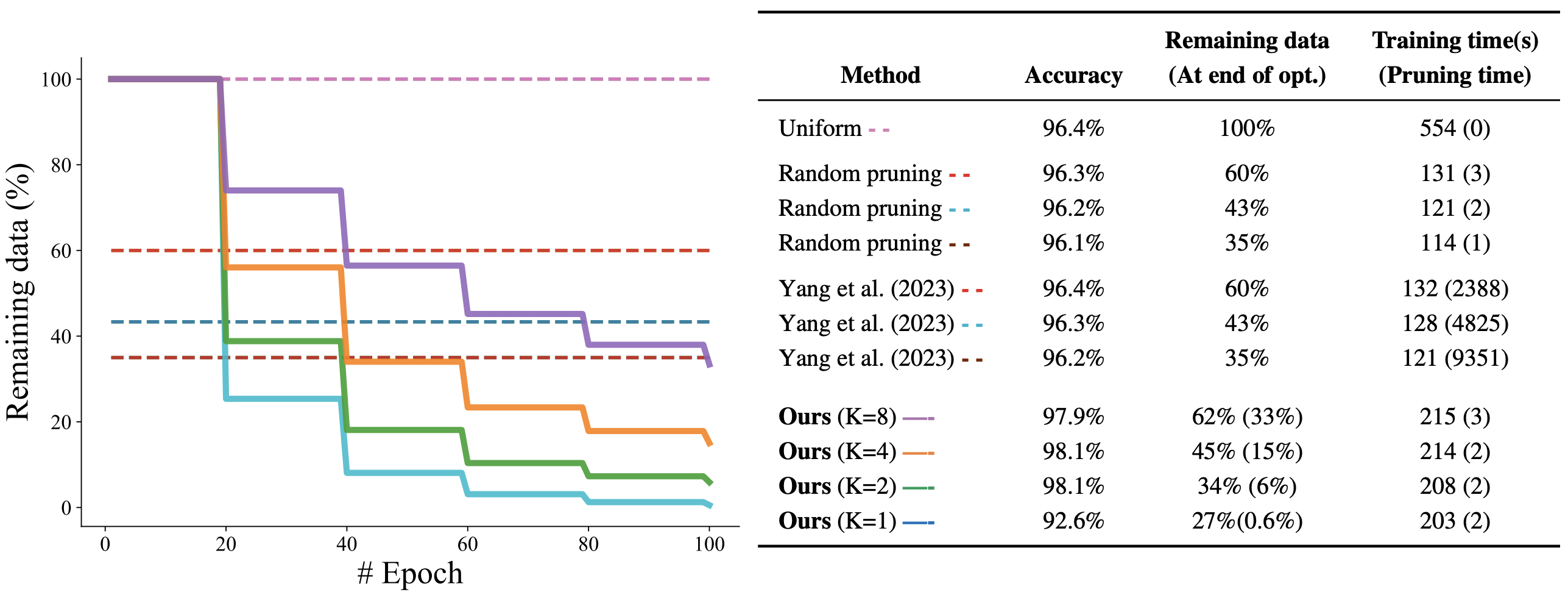
Importance sampling allows effective data pruning. We evaluate the impact of the amount of data pruned during training on a MNIST classification task.
The left
panel shows the evolution of the pruned data over time, while the right panel presents the final accuracy, the average training
set size during training and remaining data at the end of training, the total training time, and the computation time of pruning.
The figure compares a uniform sampling without data pruning, random pruning with 60%, 43%, and 35% of data pruned,
the method of Yang et al. (2023) at the same pruning rates, and our approach using a dynamic reduction factor K. Results
indicate that pruning more data accelerates execution. Our online pruning method offers greater adaptability during training
while maintaining high accuracy and minimal difference between training time and total execution time.
Abstract
Machine learning optimization often depends on stochastic gradient descent, where the precision of gradient estimation is vital for model performance. Gradients are calculated from mini-batches formed by uniformly selecting data samples from the training dataset. However, not all data samples contribute equally to gradient estimation. To address this, various importance sampling strategies have been developed to prioritize more significant samples. Despite these advancements, all current importance sampling methods encounter challenges related to computational efficiency and seamless integration into practical machine learning pipelines.
In this work, we propose a practical algorithm that efficiently computes data importance on-the-fly during training, eliminating the need for dataset preprocessing. We also introduce a novel metric based on the derivative of the loss w.r.t. the network output, designed for mini-batch importance sampling. Our metric prioritizes influential data points, thereby enhancing gradient estimation accuracy. We demonstrate the effectiveness of our approach across various applications. We first perform classification and regression tasks to demonstrate improvements in accuracy. Then, we show how our approach can also be used for online data pruning by identifying and discarding data samples that contribute minimally towards the training loss. This strategy yields significant reduction in training time with negligible to no loss in the accuracy of the model on unseen data.