Corentin Salaun1, Xingchang Huang1, Iliyan Georgiev2, Niloy Mitra2,3, Gurprit Singh1
1Max Planck Institute for Informatics, Saarbrücken, Germany 2Adobe, United Kingdom 3UCL, United Kingdom
ICPRAM 2025
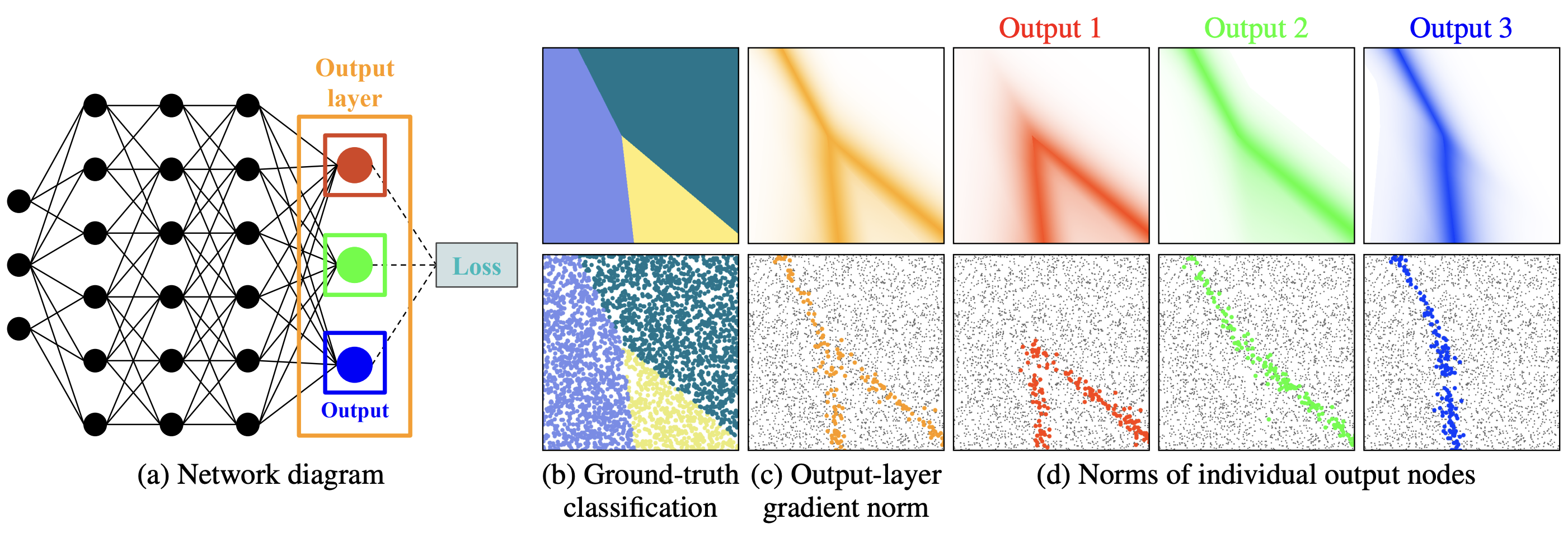
We visualize different importance sampling distributions for a simple classification task. We propose to use the
output layer gradients for importance sampling, as shown in the network diagram (a). For a given ground-truth classification
(top) and training dataset (bottom) shown in (b), it is possible to importance sample from the L2 norm of the output-layer
gradients (c) or from three different sampling distributions derived from the gradient norms of individual output nodes (d).
The bottom row shows sample weights from each distribution.
Abstract
We introduce a theoretical and practical framework for efficient importance sampling of mini-batch samples for gradient estimation from single and multiple probability distributions. To handle noisy gradients, our framework dynamically evolves the importance distribution during training by utilizing a self-adaptive metric. Our framework combines multiple, diverse sampling distributions, each tailored to specific parameter gradients. This approach facilitates the importance sampling of vector-valued gradient estimation. Rather than naively combining multiple distributions, our framework involves optimally weighting data contribution across multiple distributions.
This adapted combination of multiple importance yields superior gradient estimates, leading to faster training convergence. We demonstrate the effectiveness of our approach through empirical evaluations across a range of optimization tasks like classification and regression on both image and point cloud datasets.